Creative Commons Attribution 4.0 International Public License (CC-BY)
Abstract
The API strategy consists of a core — a generic set of rules for all government APIs — and various extensions that only pertain to a specific application or that are not maure enough for the core set.
These extensions are described in this document. It is indicated whether an extension is stable or in development.
Status of This Document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current Geonovum publications and the latest revision of this document can be found via https://www.geonovum.nl/geo-standaarden/alle-standaarden(in Dutch).
Dit is de definitieve versie van de handreiking. Wijzigingen naar aanleiding van consultaties zijn doorgevoerd.
Compared to the previous version of the API Designrules Extensions (2021-06-28) the extension API-security has been changed, and 2 extensions have been added: Hypermedia and Naming Conventions. After a public consultation round, held in the summer of 2021, these extensions have been finalized and released as stable.
1. Introduction
Dit onderdeel is niet normatief.
This document contains extensions for the API Design Rules standard.
1.1 Reading Guide
This document is part of the Nederlandse API Strategie.
API-71: Support the HAL media type for every GET response
API-72: Provide at least an href attribute for every link object
API-73: Provide self-referencing links for all resources
API-74: Provide navigational links pointing to GET operations only
API-75: Only provide navigational links when there is a clear functional goal
API-76: Treat external links as regular resource attributes
3. Security
Dit onderdeel is niet normatief.
Note
The working group has indicated this extension to be stable.
3.1 Introduction
This section describes security principles, concepts and technologies to apply when working with APIs. Controls need to be applied for the security objectives of integrity, confidentiality and availability of the API and services and data provided thereby. The (new draft of the) architecture section of the API strategy contains architecture patterns for implementing API security. This extension provides the details on the authentication & authorization capability of the API capability model detailed in the (new draft of the) architecture section of the API strategy.
The scope of this section is limited to generic security controls that directly influence the visible parts of an API. Effectively, only security standards directly applicable to interactions are discussed here.
In order to meet the complete security objectives, every implementer MUST also apply a range of controls not mentioned in this section.
Note: security controls for signing and encrypting of application level messages will be part of a separate extension, Signing and Encryption.
3.2 Transport security
One should secure all APIs assuming they can be accessed from any location on the internet. Information MUST be exchanged over TLS-based secured connections. No exceptions, so everywhere and always. One SHOULD follow the latest NCSC guidelines for TLS
API-11: Secure connections using TLS
Secure connections using TLS following the latest NCSC guidelines [NCSC.TLS].
Since the connection is always secured, the access method can be straightforward. This allows the application of basic access tokens instead of encrypted access tokens.
Even when using TLS-based secured connections information in URIs is not secured. URIs can be cached and logged outside of the servers controlled by clients and servers. Any information contained in them should therfor be considered readable by anyone with access to the netwerk being used (in case of the internet the whole world) and MUST NOT contain any sensitive information. Neither client secrets used for authentication, privacy sensitive informations suchs as BSNs nor any other information which should not be shared. Be aware that queries (anything after the '?' in a URI) are also part of an URI.
API-58: No sensitive information in URIs
Do not put any sensitive information in URIs
Even when the connection is secure URIs can be cached and logged, in systems outside the control of client and/or server.
3.3 API access patterns
Because security is about compromises one should first be aware of what access patterns need to be supported. More information on API access patterns can be found in Dutch in the architecture chapter of the Dutch API strategy
3.3.1 Machine to machine
Two different machines negotiate a secure point to point connection. One side acts as the client, the other as the server. Both sides identify and authenticate the other party.
The server authorizes access to its resources by the client based on the established identity of the client. The authorizations for a client are determined by doing a lookup to an identity store based on the established identity of the client.
Note that in Dutch government we often only identify organizations and not individual machines or their users. Therefor the access rights or permissions associated with a given identity might be far greater than needed. This is breaking the principle of least privilege.
3.3.2 Rights delegation
In the rights delegation pattern a system is granted access to a resource by and on behalf of the owner of that resource. The rights delegation access pattern can help solve the problem of machines having greater permissions/priviliges/access rights than necessary for the task at hand.
Retrieving a resource at run-time requires a resource owner, a client, an authorization server and a resource server. The resource owner (often the end user) grants permissions to the client to access resources on its behalf.
This grant is stored at the authorization server, after permissions are granted to the client to access resources on the resource server; with or without the presence of an end user.
When a resource owner provides a grant to the client, this grant SHOULD only contain the permissions the client needs to perform its intended tasks.
To deny the client access to these resources after initial permission is granted, the resource owner MUST revoke the grant at the authorization server or the grant might be revoked after a predefined expiration period.
3.3.3 Session based API access pattern
While this method is considered legacy it is in common use for handling access control to APIs, even though it conflicts with best practices for APIs. Because this pattern is more a standard web application pattern we refer to the latest NCSC guidelines on the subject of web application security for security considerations.
We consider this method to be mostly outside the scope of this document and refer to the aforementioned NCSC document for security considerations. We do provide some additional considerations for web clients in the section on HTTP-level Security.
3.4 Identification
End Users and Organizations
For identification of individual end users a pseudonym SHOULD be used when possible, to avoid exposing sensitive information about a user.
This pseudonym can optionally be translatable to actual personal information in a separate service, but access to this service should be tightly controlled and limited only to cases where there is a legal need to use this information. Furthermore using a seperate service for translation provides a moment to audit when certain information about users is requested.
Use of a Burger Service Number (BSN) is only allowed when the organization has a legal ground to do so. Even when an organization is eligible to use BSN's it is still RECOMMENDED to use a pseudonym that is only translatable to a BSN for a limited number of services/users within the organization.
An example of this can be found in the architecture of the "digitaal stelsel omgevingswet (DSO)"
For identifying government organizations use the "organisatie-identificatienummer" (OIN).
Clients
Identification of clients is different from identification of the end user or organisation using the service.
When using authorization servers, the authorization server issues the registered client a client identifier - a unique string representing the registration information provided by the client. The client identifier is not a secret; it is commonly public known and MUST NOT be relied upon for client authentication by itself. The client identifier is unique to the authorization server.
Authorization servers MUST NOT allow clients to choose or influence their client_id value.
3.5 Authentication
Authentication determines whether individuals and applications accessing APIs are really who they say they are. In the context of APIs, authentication is applicable to the End-User, i.e. the individual on behalf of whom API resources are being accessed, and to the Client, i.e. the application that accesses the API resources on behalf of the End-User.
Note that an End-User can be both a natural person as well as a legal person (organization). In case Client Authentication includes information about its governing organization, this may fulfill and obviate the need for End-User authentication. See the section "Client Credentials using OAuth 2.0" below.
3.5.1 End-User authentication
In most Use Cases that involve API interaction, authenticating the End-User on behalf of whom the API resources are accessed is required. This is typically matches with the rights delegation API access pattern.
End-User authentication is not required in situations where the API Client is solely accessing API resources on behalf of itself or its governing organization, without requiring an End-User context, but may be used nevertheless. This happens in the machine to machine API access pattern.
The following methods can be used for End-User authentication:
SAML
SAML is a standard for securely communicating assertions about an authenticated End-User from the Identity Provider to the Service Provider. Although it existed before APIs became mainstream and is not aimed at API authentication specifically, communicating Access Tokens that can be used to access API resources in the exchanged assertions is possible.
OAuth
Although technically an authorization method, OAuth [OAuth2] is used as well for authenticating End-Users themselves and providing the Client with an Access Token upon successful End-User (and Client) authentication. This Access Token can be used to make authorized API requests. Using OAuth is appropriate when authorization is not dependent on an identifiable subject, the subject is different from the End-User or the Resource Server does not require authentication of the End-User itself.
The NL GOV Assurance profile for OAuth 2.0 is included on the list of required standards by Forum Standaardisatie. The latest version of the profile can be found at https://publicatie.centrumvoorstandaarden.nl/api/oauth/.
OpenID Connect
OpenID Connect [OpenID.Core] adds an identity layer on top of OAuth, making it into an actual authentication method. It enables API Clients to verify the identity of authenticated End-Users and to obtain profile information about the End-User.
A Dutch Assurance profile for OpenID Connect is currently being drafted. It is expected to be added to the list of required standards by Forum Standaardisatie. The latest version of the draft profile can be found at https://logius.gitlab.io/oidc/.
Out of band
For some Use Cases it may be appropriate to distribute Access Tokens using an Out of band method. Out of band authentication is generally appropriate when API resources are accessed via an application that already supports a client authentication method and the End-User is rather static. Based on an End-User authentication performed, the application subsequently is provided with an Access Token for API access via a secure method.
Depending on the technology used by the applications accessing the API the Access Token may technically be communicated using a secure cookie. This however limits the technologies used to create client applications.
The Client application that accesses API resources SHOULD be authenticated, both in the machine to machine and in the rights delegation API access patterns. Also note that, although listed separately, the aforementioned methods for End-User authentication require Client authentication as well.
Note: Client Authentication is applicable to the Client accessing the API, the Client making request to the Authorization Server when applying OAuth/OpenID, or both. Client Authentication SHOULD be applied for both uses.
It is RECOMMENDED to use asymmetric (public-key based) methods for client authentication such as mTLS RFC8705 or "private_key_jwt" OpenID.
The NL GOV Assurance profile for OAuth 2.0 REQUIRES the use of private_key_jwt for full clients, native clients with dynamically registered keys, and direct access clients as mentioned in the profile.
The following methods can be used for Client authentication.
3.5.2.1 Mutual TLS authentication (mTLS)
Mutual TLS authentication, is a feature of TLS with which the Client authenticates itself to the Server using its X.509 certificate. Mutual TLS (mTLS) provides strong Client authentication for server-based Clients and cannot be used with Native or User-Agent-based Clients that are not backed with a server. Support for mTLS in combination with OAuth2 is specified in RFC8705.
In contexts where Dutch (semi) governmental organizations are involved, the X.509 certificate used for Client authentication MUST be a PKIOverheid certificate. These are x509 certificates derived from a root certificate owned by the Dutch Government. For more information on PKIOverheid see https://www.logius.nl/diensten/pkioverheid.
With Private key JWT authentication OpenID, the Client registers a public key with the Server and accompanies every API request with a JWT signed using this key. This Client Authentication method is part of the OpenID Connect standards for Clients authenticating to the OpenID Provider, but the use of Private key JWT Client authentication is not limited to this use case.
This authentication method may be used with Clients that are able to securely store asymmetric private keys and sign JWT's with this key.
In contexts where Dutch (semi) governmental organizations are involved, the certificate used for signing the Private key JWT's MUST be a PKIOverheid certificate. In case the certificate is included in the JWT header, it includes identification of the client and registration of the public key may not be necessary.
The NL GOV Assurance profile for OAuth 2.0 REQUIRES the use of private_key_jwt for full clients, native clients with dynamically registered keys, and direct access clients as mentioned in the profile.
3.5.2.3 Client secrets
Clients SHOULD NOT be authenticated using client secrets. Methods using asymmetric keys are RECOMMENDED instead of client secrets, as they are both more secure and key management is easier, in particular when deployed at scale. Various methods exists for authenticating clients using secrets. Methods including Client authentication using HTTP Basic authentication or communicating client credentials in the request body are prone to credential theft.
3.5.2.4 Client authentication and Public clients
In Use Cases that involve Native and User-Agent based Clients, strong Client authentication is generally not possible. Whereas it may be possible for individual Clients to implement a decent means of Client authentication (e.g. by using the Web Crypto API in User-Agent based Clients), the Server cannot make any assumptions about the confidentiality of credentials exchanged with such Clients.
When dealing with Use Cases involving Native and User-Agent based Clients, the policies and standards described in Section HTTP level security SHOULD be followed, as well as best practices [OAuth2.Browser-Based-Apps] and [RFC8252], which are defined for use with OAuth but may be applicable for API communication in general.
3.5.2.5 Other Authentication Methods
An API Server (Resource Server) or Authorization Server MAY support any suitable authentication scheme matching their security requirements. When using other authentication methods, the authorization server MUST define a mapping between the client identifier (registration record) and authentication scheme.
Some additional authentication methods are defined in the OAuth Token Endpoint Authentication Methods registry, and may be useful as generic client authentication methods beyond the specific use of protecting the token endpoint.
3.5.3 Client Credentials using OAuth 2.0
In Use Cases where the Client is solely accessing API resources on behalf of itself or its governing organization, without requiring an End-User context, Client authentication using the OAuth 2.0 Client Credentials grant type can be appropriate. In such cases, the Authorization Server securely provides Client credentials to the Client upon registration (e.g. via an API Developer portal or out of bound process) and the Client uses these credentials to obtain an Access Token from the Authorization Server. The Access token than is used to access the API (Resource Server) using the Access Token.
Note that existing Client Credentials, such as a PKIoverheid X.509 certificate, MAY be used. This preempts the need for providing additional credentials. Any of the above mentioned Client Authentication methods can be applied with the Client Credential flow.
Usage of the Client Credential method with OAuth is RECOMMENDED over direct authorization by the API Server (Resource Server), even if the authorization decision can be based directly on Client Authentication. This externalizes the authorization decision from the API implementation, allowing for easier modifications and management of both the decision logic as well as client authentication methods.
3.6 Authorization
It is RECOMMENDED to use token-based access to APIs. REST APIs SHOULD NOT maintain session state on the server. The authentication and authorization of a request SHOULD NOT depend on sessions. Instead, a token has to be sent with each request.
API-13: Accept tokens as HTTP headers only
There is an inherent security issue when passing tokens as a query parameter, because most Web servers store query parameters in the server logs.
Using tokens, a distinction is made between authorized and non-authorized services and related headers:
Authorized
Authorization: Bearer <token>
Non-authorized
X-Api-Key: <api-key>
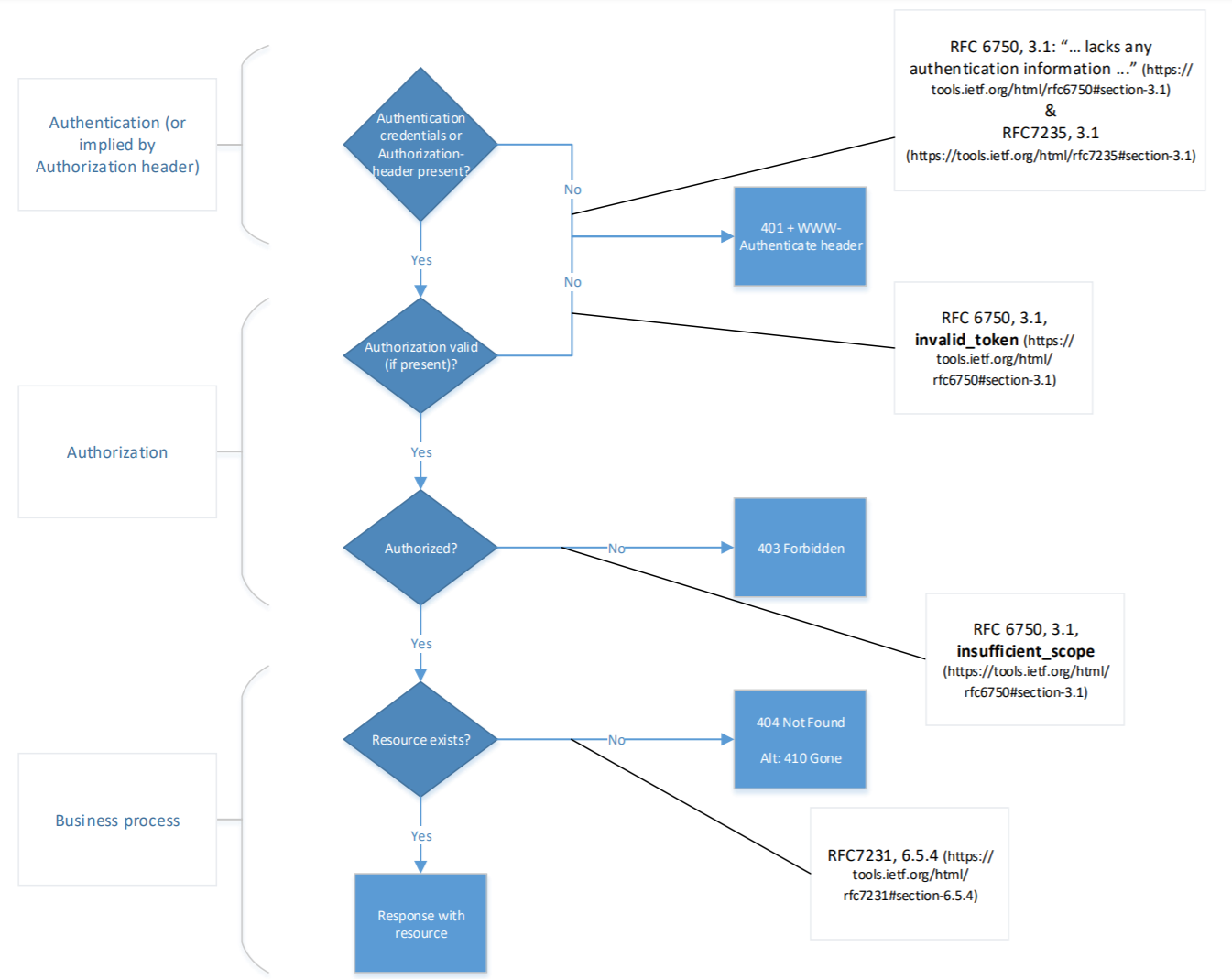
In case the proper headers are not sent, then there are no authentication details available and a status error code 403 Forbidden is returned.
API-52: Use OAuth 2.0 for authorization with rights delegation
This is in line with the way the OAuth standard appears on the comply or explain list of Forum Standaardisatie.
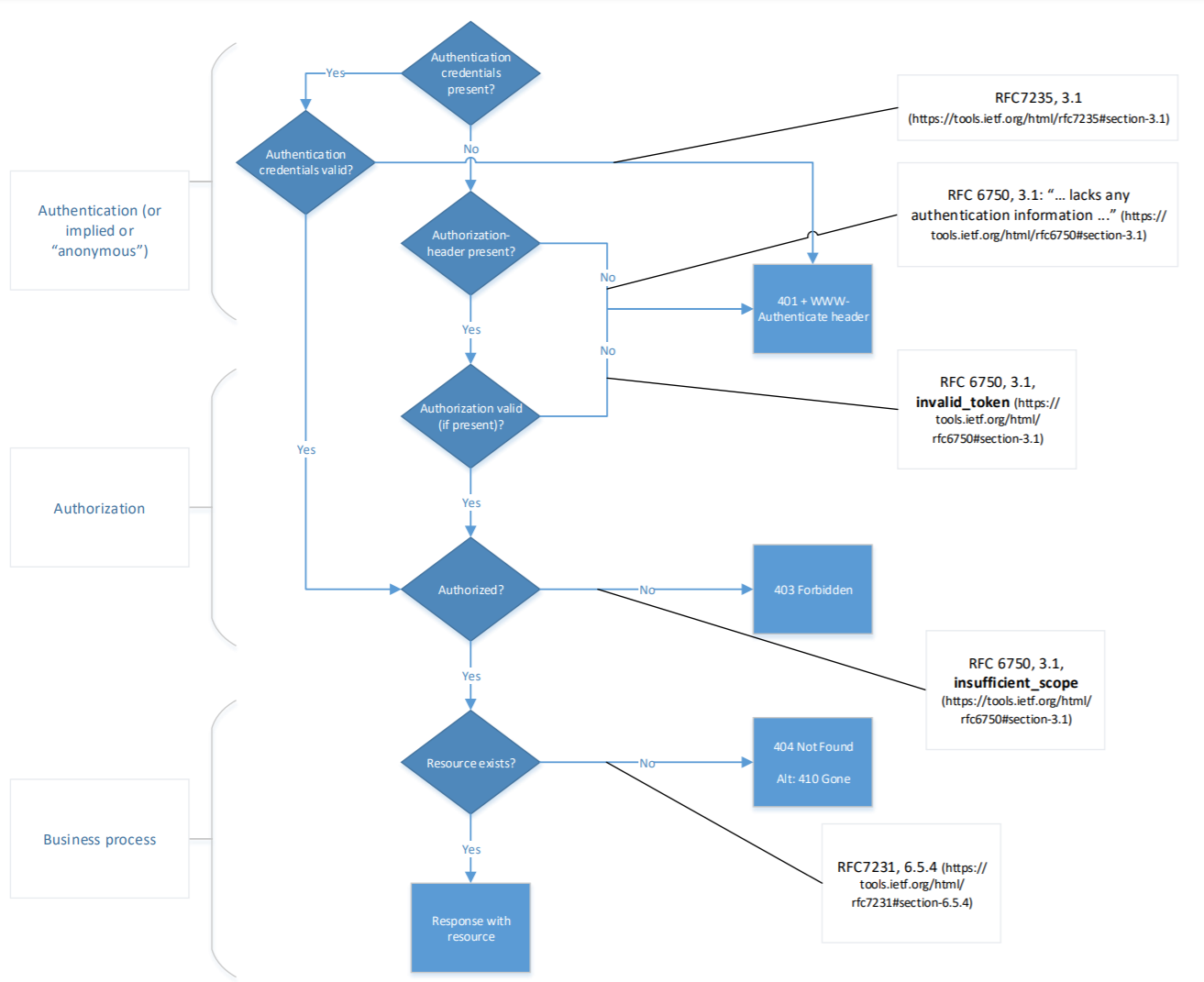
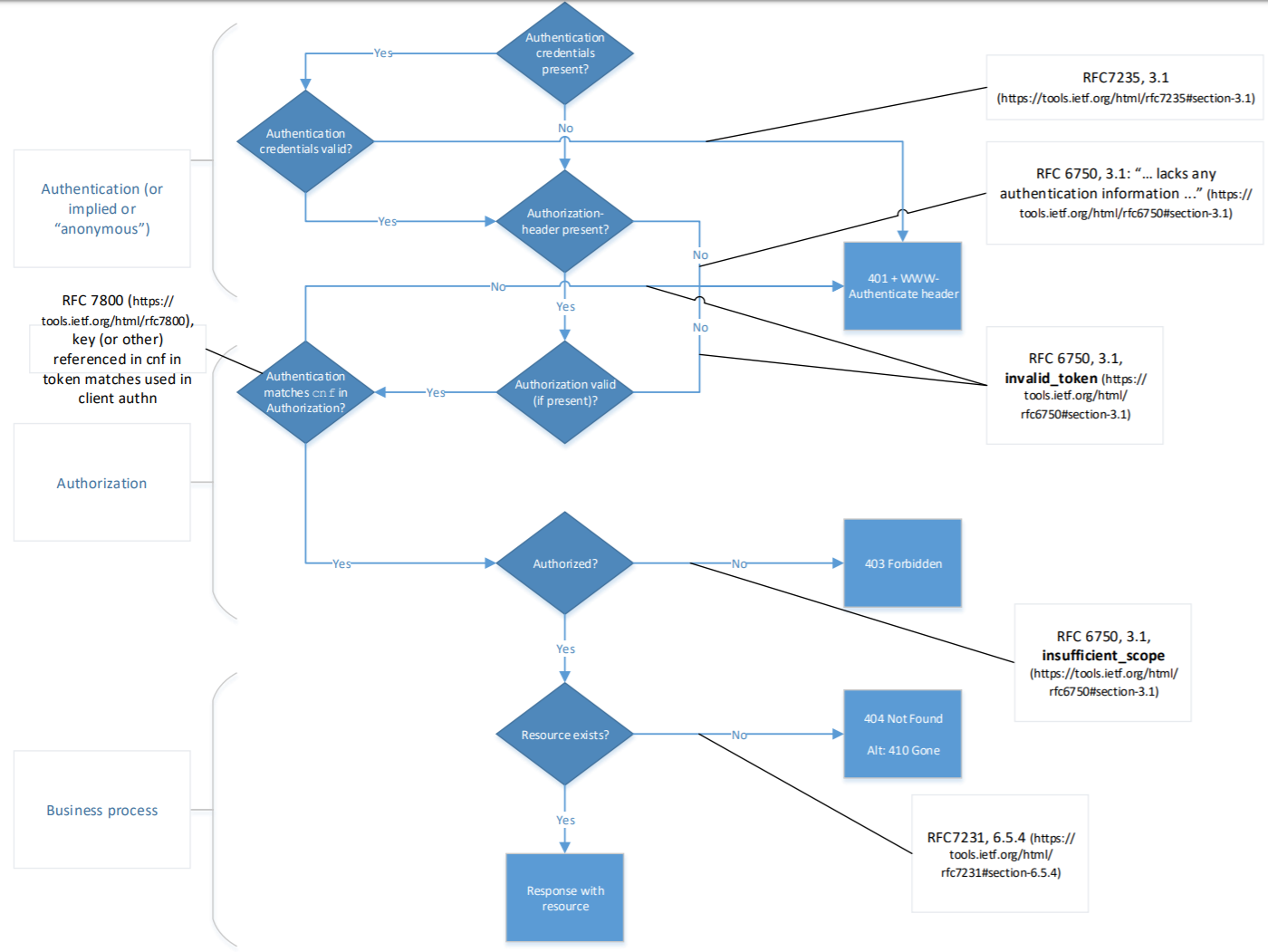
In a production environment as little information as possible is to be disclosed. Apply the following rules for returning the status error code 401 Unauthorized, 403 Forbidden, and 404 Not Found.
Note that authentication in the cases below is typically client authentication, and the Authorization header contains information on the End-User authorization and authentication, if applicable.
Note that usage of the Authorization header is part of the OAuth2 specifications.
Implicit authentication
When authentication is implicit or when just the presence of an Authorization header is enough for authentication and/or authorization: use the flow chart in figure 1 to determine the correct error code.
When authentication is explicit, that is the authentication credentials are actively verfied when present, use the flow chart in figure 2 to determine the correct error codes.
Explicit authentication while matching client authorization (cnf)
When authentication is explicit and there is a check whether the provided authorization confirmation claim (cnf, see [rfc7800]) matches the credentials provided for authentication use the flow chart in figure 3 to esteblish the correct error codes.
Figure 3: authentication is explicit, and client authorization confirmation claim (cnf) matches authentication.
The guidelines and principles defined in this extension are client agnostic. When implementing a client agnostic API, one SHOULD at least facilitate that multi-purpose generic HTTP-clients like browsers are able to securely interact with the API. When implementing an API for a specific client it may be possible to limit measures as long as it ensures secure access for this specific client. Nevertheless it is advised to review the following security measures, which are mostly inspired by the OWASP REST Security Cheat Sheet
Even while remaining client agnostic, clients can be classified in four major groups. This is much in line with common practice in OAuth2. The groups are:
Web applications.
Native applications.
Browser-based applications.
System-to-system applications.
This section contains elements that apply to the generic classes of clients listed above. Although not every client implementation has a need for all the specifications referenced below, a client agnostic API SHOULD provide these to facilitate any client to implement relevant security controls.
Most specifications referenced in this section are applicable to the first three classes of clients listed above.
Security considerations for native applications are provided in [OAUth2 for Native Apps]](https://tools.ietf.org/html/rfc8252), much of which can help non-OAuth2 based implementations as well.
For browser-based applications a subsection is included with additional details and information.
System-to-system (sometimes called machine-to-machine) may have a need for the listed specifications as well. Note that different usage patterns may be applicable in contexts with system-to-system clients, see above under Client Authentication.
3.7.1 Security Headers
There are a number of security related headers that can be returned in the HTTP responses to instruct browsers to act in specific ways. However, some of these headers are intended to be used with HTML responses, and as such may provide little or no security benefits on an API that does not return HTML. The following headers SHOULD be included in all API responses:
Header
Rationale
Cache-Control: no-store
Prevent sensitive information from being cached.
Content-Security-Policy: frame-ancestors 'none'
To protect against drag-and-drop style clickjacking attacks.
Content-Type
To specify the content type of the response. This SHOULD be application/json for JSON responses.
Strict-Transport-Security
To require connections over HTTPS and to protect against spoofed certificates.
X-Content-Type-Options: nosniff
To prevent browsers from performing MIME sniffing, and inappropriately interpreting responses as HTML.
X-Frame-Options: DENY
To protect against drag-and-drop style clickjacking attacks.
Access-Control-Allow-Origin
To relax the 'same origin' policy and allow cross-origin access. See CORS-policy below
The headers below are only intended to provide additional security when responses are rendered as HTML. As such, if the API will never return HTML in responses, then these headers may not be necessary. However, if there is any uncertainty about the function of the headers, or the types of information that the API returns (or may return in future), then it is RECOMMENDED to include them as part of a defense-in-depth approach.
Header
Rationale
Content-Security-Policy: default-src 'none'
The majority of CSP functionality only affects pages rendered as HTML.
Feature-Policy: 'none'
Feature policies only affect pages rendered as HTML.
Referrer-Policy: no-referrer
Non-HTML responses SHOULD not trigger additional requests.
In addition to the above listed HTTP security headers, web- and browser-based applications SHOULD apply Subresource Integrity SRI. When using third-party hosted contents, e.g. using a Content Delivery Network, this is even more relevant. While this is primarily a client implementation concern, it may affect the API when it is not strictly segregated or for example when shared supporting libraries are offered.
3.7.2 CORS-policy
API-50: Use CORS to control access
Use CORS to restrict access from other domains (if applicable).
Modern web browsers use Cross-Origin Resource Sharing (CORS) to minimize the risk associated with cross-site HTTP-requests. By default browsers only allow 'same origin' access to resources. This means that responses on requests to another [scheme]://[hostname]:[port] than the Origin request header of the initial request will not be processed by the browser. To enable cross-site requests API's can return a Access-Control-Allow-Origin response header. It is RECOMMENDED to use a whitelist to determine the validity of different cross-site request. To do this check the Origin header of the incoming request and check if the domain in this header is on the whitelist. If this is the case, set the incoming Origin header in the Access-Control-Allow-Origin response header.
Using a wildcard * in the Access-Control-Allow-Origin response header is NOT RECOMMENDED, because it disables CORS-security measures. Only for an open API which has to be accessed by numerous other websites this is appropriate.
3.7.3 Browser-based applications
A specific subclass of clients are browser-based applications, that require the presence of particular security controls to facilitate secure implementation. Clients in this class are also known as user-agent-based or single-page-applications (SPA).
As with the (draft) OAuth 2.0 for Browser-Based Apps, browser-based application can be split into three architectural patterns:
JavaScript applications with a Backend; with this class of applications, the Backend is the confidential client and should intermediate any interaction, with tokens never ending up in the browser. Effectively, these are not different from regular web-application for this security facet, even though they leverage JavaScript for implementation.
JavaScript applications that share a domain with the API (resource server); these can leverage cookies marked as HTTP-Only, Secure and SameSite.
JavaScript applications without a Backend; these clients are considered public clients, are potentially more suspect to several types of attacks, including Cross-Site Scripting (XSS), Cross Site Request Forgery (CSRF) and OAuth token theft. In order to support these clients, the Cross-Origin Resource Sharing (CORS) policy mentioned above is critical and MUST be supported.
Apply a whitelist of permitted HTTP Methods e.g. GET, POST, PUT. Reject all requests not matching the whitelist with HTTP response code 405 Method not allowed.
3.7.5 Validate content types
A REST request or response body SHOULD match the intended content type in the header. Otherwise this could cause misinterpretation at the consumer/producer side and lead to code injection/execution.
Reject requests containing unexpected or missing content type headers with HTTP response status 406 Unacceptable or 415 Unsupported Media Type.
Avoid accidentally exposing unintended content types by explicitly defining content types e.g. Jersey (Java) @consumes("application/json"); @produces("application/json"). This avoids XXE-attack vectors for example.
It is common for REST services to allow multiple response types (e.g. application/xml or application/json, and the client specifies the preferred order of response types by the Accept header in the request.
Do NOT simply copy the Accept header to the Content-type header of the response.
Reject the request (ideally with a 406 Not Acceptable response) if the Accept header does not specifically contain one of the allowable types.
Services (potentially) including script code (e.g. JavaScript) in their responses MUST be especially careful to defend against header injection attack.
Ensure sending intended content type headers in your response matching your body content e.g. application/json and not application/javascript.
3.7.6 HTTP Return Code
HTTP defines status codes. When designing a REST API, don't just use 200 for success or 404 for error. Always use the semantically appropriate status code for the response.
3.7.7 HTTP header filtering
Realizations may rely on internal usage of HTTP-Headers. Information for processing requests and responses can be passed between components, that can have security implications.
For instance, this is commonly practices between a reverse proxy or TLS-offloader and an application server. Additional HTTP headers are used in such example to pass an original IP-address or client certificate.
Implementations MUST consider filtering both inbound and outbound traffic for HTTP-headers used internally.
Primary focus for inbound filtering is to prevent injection of malicious headers on requests.
For outbound filtering, the main concern is leaking of information.
3.7.8 Error handling
Respond with generic error messages - avoid revealing details of the failure unnecessarily.
Do not pass technical details (e.g. call stacks or other internal hints) to the client.
4. Versioning
Dit onderdeel is niet normatief.
Warning
This extension is still in development and can be modified at any time.
4.1 Deprecation of a major API version
Major API releases should always be backward incompatible. In case a new API release does not result in backward incompatibility, it does not warrant a full version increase and it is merely a minor release. In case a major release takes place, all (potential) clients have to implement the new version.
As clients cannot be broken, a migration from the previous to the new release cannot happen abruptly. After the launch the new version, the previous version has to be available in production as well. As not to maintain the previous version indefinitely and to encourage clients to use the new version, a transition period is communicated for users to adjust their code to the new version. This period is referred to as deprecation period. The duration of this period may very per API. Typically, the deprecation period lasts 6 months, but not more than one year. From a maintenance perspective, at most two major versions (one of which is the deprecated version) should be available in production concurrently. Communication with users is crucial during this period. The following points have to be communicated:
A link to the (documentation of the) new API version;
Deprecation period with the exact date the deprecated version will be taken offline;
Migration plan to easily transition to the new version;
Overview of added, changed or removed features;
Breaking changes for the current implementation;
Contact details to request an extension of the deprecation period.
These should be communicated using the following channels:
To the e-mail accounts of the users (if known)
Clearly visible in the documentation of the previous version;
Using a Warning response header in all responses from the old API.
A step-by-step approach:
Launch new version;
Determine deprecation period;
Write migration plan;
Communicate in the API documentation of the old version;
Communicate per e-mail, Web forum and other channels;
Add Warning response header to the old version;
Check logs to monitor the usage of the old version during the deprecation period;
Shut down end-point of the old version at the planned date and monitor feedback;
No feeedback related to the old version within two weeks, remove the old version (including docs);
4.2 The Warning response header
The Warning reponse header (see: RFC 7234) has the status code 299 ("Miscellaneous Persistent Warning") and the API endpoint (including version number) as the warn-agent of the warning, followed by the warn-text with the human-readable warning. For example:
Warning: 299 https://service.../api/.../v1 "Deze versie van de API is verouderd en zal uit dienst worden genomen op 2020-02-01. Raadpleeg voor meer informatie hier de documentatie: https://omgevingswet.../api/.../v1".
Users should have sufficient time to phase out the old API. A period of 6 to 12 months is recommended.
API-21: Inform users of a deprecated API actively
Using the Warning response header in all responses of the deprecated APIs, users are informed of the deprecation and upcoming removal date.
5. Naming conventions
Dit onderdeel is niet normatief.
Note
The working group has indicated this extension to be stable.
Although according to the URI specification [rfc3986] URI's are case sensitive, except the scheme/protocol (e.g. https://) and domain (e.g. api.example.org) parts, this section describes design rules related to URI's to ensure interoperability among implementations.
Specifically, design rules related to the path segments and query strings of URI's that are used to specify API resource locations are described.
5.1 Path segments
First, in order to avoid compatibility issues with web servers and frameworks that do not handle case sensitivity of URI's well, the use of spinal-case path segments is preferred over camelCase. Also, it is a more common implementation choice for path segments than snake_case.
API-59: Use spinal-case for path segments
In case path segments include compound words, the individual words are written in lower case and may be separated with hyphens. For example, a resource representing a collection of organisatie codes, results in either a path segment organisatie-codes or organisatiecodes.
Also, the use of special characters used in path segments should be reduced to a minimum. Therefore, the use of diacritics and punctuation marks (other than hyphens, which are used in the spinal-case convention) must be avoided.
API-60: Normalize characters with diacritics to their base characters for path segments
In case path segments include diacritics (e.g. accents), these characters are normalized to their base characters. For example, a resource scènes results in path segment scenes.
API-67: Omit symbols and punctuation marks other than hyphens from path segments
Symbols and punctuation marks, other than hypens, must be omitted from path segments. For example:
https://api.example.org/v1/schemas (' of schema's is omitted)
https://api.example.org/v1/hotel-restaurants (- is preserved)
With regards to naming, resources must use clear, descriptive names that expresses what the respective resources represent. Therefore, the use of nonstandard abbreviations and superfluous prefixes should be avoided in resource names.
API-61: Do not explicitly indicate that a resource is an API
Use resource names as path segments (e.g. gebouwen) and do not explicitly mention that the resource is an API in the name (e.g. gebouwen_api).
API-62: Do not use file extensions in path segments
Preferably use content negotiation using the Accept header
API-63: Do not use nonstandard abbreviations as resource names
Avoid using nonstandard abbreviations for naming resources (e.g. /coords instead of /coordinates). This does not apply to standard or broadly used abbreviations (e.g. bagNummeraanduiding).
5.2 Query parameters
API-69: Use lowerCamelCase for query parameter keys
Keys of query parameters must be written in lowerCamelCase. This naming convention aligns nicely with JSON property names and plays well with client side libraries such as JavaScript. Query parameters should not be prefixed with an underscore (e.g. _sort), but in case prefixing elements with underscores is required (e.g. for data API's where field names are dynamically defined by clients or to align with HAL conventions), an underscore prefix must only be used to denote meta-parameters such as `_sort`, `_expand` and `_filter`.
6. JSON
Dit onderdeel is niet normatief.
Warning
This extension is still in development and can be modified at any time.
JavaScript Object Notation (JSON) [rfc7159] is a format, just like XML, to serialize, store and transfer data. JSON is the primary representation format for APIs. In contrast to XML, JSON has a compact notation, for example:
{
"naam": "Jan",
"geboortejaar": 1983
}
API-22: JSON first - APIs receive and send JSON
APIs receive and send JSON.
API-23: APIs may provide a JSON Schema
APIs may provide an additional JSON Schema for data validation by the consumer (not being the OAS file).
API-24: Support content negotiation
Besides JSON, APIs should support other representations like XML and RDF using the default HTTP content negotiation mechanism. In case the requested format cannot be provided, a 406 Not Acceptable response is sent.
API-25: Check the Content-Type header value
Check the Content-Type header is application/json or another supported content types, otherwise send the HTTP status code 415 Unsupported Media Type.
API-26: Define field names in camelCase
Define field names in such a way that the first word starts with a lower case letter and subsequent words start with a capital letter, with no intervening spaces or punctiation.
API-64: Do not use compound words for nested objects
Use nested JSON objects (e.g. adres.straat) instead of compound words (e.g. adres_straat or adresStraat) to represent information that is hierarchically nested.
API-65: Use enumerations only for fixed sets of values that are unlikely to change
Enumerations are assumed closed sets of values that are complete and not altered or extended. Changing or extending allowed values in an enum most likely imposes incompatibility issues and must be treated as a breaking change. Therefore, enumerations must only be used when:
the list of allowed values is complete and does not change (within a single API version); and
the API provider has full control over the enumeration values or can guarantee that these will not change.
In all other cases, use strings instead of enumerations and mention the currently allowed values in the API documentation.
API-68: Use meaningful enumeration values
When using enumerations, ensure to use enumeration values that are meaningful to users of the API. For example, use values such as `FEMALE` to depict a gender, not `F` (a code), `1` (an ID), or `true` (a boolean).
API-66: Use UPPER_SNAKE_CASE for enumeration values
When using enumerations, define its values using UPPER_SNAKE_CASE.
This rule does not apply when using lists of values that are standardized outside of the scope of the API specification, such as:
A future-proof API does not have envelopes (correct):
{
"naam": "Jan",
"geboortejaar": 1983
}
API-29: Support JSON request body for POST and PUT operations
Request bodies for POST and PUT operations should at least support the JSON media type(application/json). Media types designed for use in HTML forms (application/x-www-form-urlencoded or multipart/form-data) should not be supported. Other media types are allowed.
What is the difference? Media type application/json is encoded as:
{
"Name": "John Smith",
"Age": 23
}
Whereas media type application/x-www-form-urlencoded is encoded as:
Name=John+Smith&Age=23
7. Filtering
Dit onderdeel is niet normatief.
Warning
This extension is in development and may be modified at any time.
Base URLs of resources should be as straightforward as possible. Complex result filters, sorting, and advanced querying (restricted to a single resource) are implemented as query paramters on top of the base URL.
Filtering uses unique query parameters that correspond to the queryable fields. If you would like to request a list of applications from the end point /aanvragen/ and limit this to open applications, use the request GET /aanvragen?status=open gebruikt. In this example status is a queryable field.
API-30: Use query parameters corresponding to the queryable fields
Use uniqe query parameters that correspond to the fields that can be queried.
This approach can be applied to nested properties as well. This is the collection:
All objects with the status actief can be filtered using ?status=actief. Filtering objects with code 0000 of the property overheid at the same time, this relates to a nested property. In this case, use the dot notation (like JavaScript): ?status=actief&overheid.code=0000.
8. Sorting
Dit onderdeel is niet normatief.
Warning
This extension is in development and may be modified at any time.
API-31: Use the query parameter sort to apply sorting
To sort, use the query parameter sort (used to be sorteer which is deprecated now). This query parameter takes a comma-separated list of field names to be used in the sort. Prefixing a filed name with a minus sign (*-*), the field is sorted in descending order.
A few examples:
Request
Explanation
GET /aanvragen?sort=-prio
Retrieves a list of aanvragen sorted by the property prio in descending order.
GET /aanvragen?sort=-prio,aanvraagDatum
Retrieves a list of aanvragen sorted by the property prio in descending order. Within a specific value of prio, the objects are sorted by aanvraagDatum in ascending order.
9. Customization
Dit onderdeel is niet normatief.
The user of an API does not always require the complete representation (i.e. all attributes) of a resource. Providing the option to select the required attributes in the request reduces network traffic (relevant for light-weight applications), simplifies the use of the API and makes it adjustable (fit-for-use). The query parameter fields supports this usage. The query parameter accepts a comma-separated list of field names. The result is a custom representation.
The following example request retrieves sufficient information to show a sorted list of applications (*aanvragen*):
GET /aanvragen?fields=id,onderwerp,aanvrager,wijzigDatum&status=open&sorteer=wijzigDatum`
By applying the aforementioned fields parameter, the contents of the body can be customized as required.
API-09: Implement custom representation if supported
Provide a comma-separated list of field names using the query parameter fields te retrieve a custom representation. In case non-existent field names are passed, a 400 Bad Request error message is returned.
10. Search
Dit onderdeel is niet normatief.
Warning
This extension is in development and may be modified at any time.
Sometimes, straightforward filters are not sufficient and the capabilities of full-text search engines are required. APIs support full-text search using the query parameter search (used to be 'zoek' which is now deprecated). The result is returned in the same representation.
API-32: Use the query parameter search for full-text search
APIs support full-text searching using the query parameter zoek.
Examples combining filtering, sorting, and searching:
Request
Explanation
GET /aanvragen?sort=-wijzigingDatum
Retrieves a list of aanvragen sorted by wijzigingsDatum in descending order
GET /aanvragen?status=gesloten&sort=-wijzigingDatum
Retrieves a list of aanvragen filtered by the status property set to gesloten and sorted by wijzigingsDatum in descending order
GET /aanvragen?search=urgent&status=open&sort=-prio,aanvraagDatum
Retrieves a list of aanvragen containing the word urgent and filtered by the status property set to open. The list is sorted by prio in descending order and subsequently sorted by aanvraagDatum in ascending order.
10.1 Wildcards
API-33: Support both * and ? wildcard characters for full-text search APIs
Full-text search APIs should support two wildcard characters:
* Matches zero or more (non-space) characters
? Matches exactly one (non-space) character
For example, he* matches any string starting with he, like hek, hemelwaterafvoer, et cetera. The search string he? only matches 3-letter strings that start with he, like hek, heg, et cetera.
Find below some base rules for wildcard searches:
A search term may contain multiple wildcard characters.
A search term may contain a combination of wildcard characters. For example m*?? matches any string that starts with m and has three or more characters.
Spaces (URL-encoded as %20) are used as word boundaries and wildcard matching only operates within a single word. For example, r*te* matches the string ruimtelijk, but not the phrase ruimtetekort.
Wildcards only operate on fields that contain alphanumerical values.
10.2 Aliases for common queries
To improve the API experience, common queries should be provided as end point. For example, aanvragen that have the status property set to gesloten and sorted by wijzigingsDatum in descending order, i.e. recently closed applications, can be retrieved using the following end point:
GET /aanvragen/recent-gesloten
11. Temporal
Dit onderdeel is niet normatief.
Warning
This extension is in development and may be modified at any time.
Information about a resource may change over time. Time travelling is a default mechanism to request information about a specific moment in time is. From the perspective of time travelling using an API, there are three important moments in time:
Moment in time
Description
Geldig
This is a moment in time on which the data returned is valid (geldig) in reality.
Beschikbaar
This is a moment in time on which the data returned is available (beschikbaar) using the same API.
In werking (getreden op)
This is a moment in time on which the data returned became legally effective (in werking getreden op).
The base principle for time travelling is as follows:
If no specific date is supplied, tehn the most recent, valid information is returned. If no valid versions exists yet, then the most recent known version is returned;
If a specific date is supplied, it is passed as a a query parameter in the URI.
Supplying a specific date, use the following query parameters respectively:
date on which the data is valid (geldigOp);
date on which the data are available (beschikbaarOp);
date on which the date became legally effectiven (inWerkingOp).
The values of these three query parameters in the URI are structured like this (based on RFC3339 / ISO 8601):
Parameter
Value
geldigOp
YYYY-MM-DD
beschikbaarOp
YYYY-MM-DDThh:mm:ss.s
inWerkingOp
YYYY-MM-DD
Value
Description
YYYY
Four-digit year
MM
Two-digit month (01 = January, etc.)
DD
Two-digit day of the month (01 to 31)
hh
Two-digit hour (00 to 23) (am / pm not allowed)
mm
Two-digit minute (00 to 59)
ss
Two-digit second (00 to 59)
s
One or more digits to represent the decimal fraction of a second
11.1 Level of support
Time travelling is an optional mechanism with optional features. It may be that:
time travelling is not supported at all;
the notion legally effective is not supported;
time travelling to the future is not supported.
Users have to be informed of the invalid/not-supported requests when processing time travelling requests:
Not supported?
HTTP status code and explanation
Time travelling
HTTP/1.1 403 Content-Type: application/problem+json Content-Language: nl { "type": ".../id/<c>/parameter/TijdreizenNietOndersteund", "title": "{Het verzoek is begrepen, maar de tijdreisparameters worden niet ondersteund}", "status": 403, "detail": "{Tijdreizen wordt niet ondersteund, verwijder alle tijdreisparameters}", "instance": "/resource/#id"}
Legally effective
HTTP/1.1 403 Content-Type: application/problem+json Content-Language: nl { "type":".../id/<c>/parameter/InWerkingTredingNietOndersteund’", "title": "{Het verzoek is begrepen, maar de tijdreisparameter ‘inWerkingOp’ wordt niet ondersteund}", "status": 403, "detail": "{Tijdreizen met een inwerkingstredingsmoment wordt niet ondersteund, verwijder de parameter ‘inWerkingOp’}", "instance": "/resource/#id"}
Future
HTTP/1.1 403 Content-Type: application/problem+json Content-Language: nl { "type": ".../id/<c>/parameter/ToekomstNietOndersteund", "title": "{Het verzoek is begrepen, maar tijdreisparameters mogen geen tijdstip in de toekomst bevatten” }", "status": 403, "detail": "{Tijdreizen naar de toekomst wordt niet ondersteund, verwijder de tijdreisparameters of gebruik een tijdstip in het verleden}", "instance": "/resource/#id"}
11.2 Robustness
Users have to be informed of the lack of historical data and general requests in a resource collection when processing time travelling requests:
Request
HTTP status code and explanation
Specific resource
HTTP/1.1 404 Content-Type: application/problem+json Content-Language: nl {"type": ".../id/<c>/BestaatNiet", "title": "De gevraagde versie bestaat niet.", "status": 404, "detail": "Versie 2017-01-01 van regeling 123 bestaat niet.", "instance": "/regelingen/v1/123?geldigOp=2017-01-01"}
This extension is in development and may be modified at any time.
REST APIs for handling geospatial features may provide spatial filtering. There is a distinction between retrieving geometries in the result (response) and supplying a spatial filter in the call (request). When requesting parcel information, users do not necessarily require the geometry. A name or parcel ID may be sufficient.
API-34: Support GeoJSON for geospatial APIs
For geospatial APIs, preferably use the GeoJSON format [rfc7946].
12.1 Result (response)
In a JSON API the geometry is returned as GeoJSON, wrapped in a separate GeoJSON object.
API-35: Embed GeoJSON as part of the JSON resource
When a JSON (application/json) response contains a geometry, represent it in the same way as the geometry object of GeoJSON.
A spatial filter can be complex and large. It is best practice to supply complex queries in the body, not in the request URI. Since GET may not have a payload (although supported by some clients) use a POST request to a separate endpoint. For example, a GEO query to all panden where the geometry in the field _geo (there may be multiple geometry fields) contains a GeoJSON object (in this case a Point, so one coordinate pair):
API-36: Provide a POST endpoint for geo queries
Spatial queries are sent in a POST to a dedicated endpoint.
// POST /api/v1/panden/_zoek with request body:
{
"_geo": {
"contains": {
"type": "Point",
"coordinates": [5.9623762, 52.2118093]
}
}
}
Other geospatial operators like intersects or within can be used as well.
API-37: Support mixed queries at POST endpoints
The POST endpoint is preferably set up as a generic query endpoint to support combined queries:
API-38: Put results of a global spatial query in the relevant geometric context
In case of a global query /api/v1/_zoek, results should be placed in the relevant geometric context, because results from different collections are retrieved. Express the name of the collection to which the results belongs in the singular form using the property type. For example:
The default CRS (Coordinate Reference System) for GeoJSON is WGS84. This is the global coordinate reference system that can be applied world-wide. Due the datum and the tectonic displacements it is not accurate enough for local coordinate reference systems like ETRS89 (EPSG:4258, European), or RD/Amersfoort (EPSG:28992, Dutch).
Since most client-side mapping libraries use WGS84, the W3C/OGC working group Spatial Data on the Web recommends to use this as the default coordinate reference system. Thus, spatial data can be mapped without any complex transformations. The API strategy caters for this supporting not only ETRS89 and RD/Amersfoort, but also WGS84 and Web Mercator (EPSG:3857).
API-39: Use ETRS89 as the preferred coordinate reference system (CRS)
General usage of the European ETRS89 coordinate reference system (CRS) is preferable, but is not necessarily the default CRS. Hence, the CRS has to be explicitly included in each request.
The CRS can be specified for request and response individually using custom headers: RD/Amersfoort, ETRS89, WGS84, and Web Mercator.
The guiding priciples for CRS support:
Source systems record coordinates as they enter the system (legal context);
Define a default CRS in the API, if the consumer does not specify the CRS it is assumed it uses the default.
Coordinate reference systems API strategy: request/response in RD; ETRS89; WGS84; Web Mercator;
Consider no-regret: record both in ETRS89 and RD/Amersfoort instead of on-the-fly transformation;
Use RDNAPTRANS™ 2018 to transform RD/Amersfoort to ETRS89 (correction grid);
Presentation depending on context (e.g. user requirements);
Exchange format (notation) ETRS89 and WGS84 X Y in decimal degrees: DD.ddddddddd (for example: 5.962376256, 52.255023450)
Exchange format (notation) RD and Web Mercator X Y in meters: 195427.5200 311611.8400
API-40: Pass the coordinate reference system (CRS) of the request and the response in the headers
The coordinate reference system (CRS) for both the request and the response are passed as part of the request headers and reponse headers. In case this header is missing, send the HTTP status code 412 Precondition Failed.
The following headers are purely meant for negotiation between the client and the server. Depending on the application, the request not only contains geometries but also specific meta data, e.g. the original realistion including the collection date.
Request and response may be based on another coordinate reference system. This applies the HTTP-mechanism for content negotiation. The CRS of the geometry in the request (request body) is specified using the header Content-Crs.
HTTP header
Value
Explanation
Content-Crs
EPSG:4326
WGS84, global
Content-Crs
EPSG:3857
Web Mecator, global
Content-Crs
EPSG:4258
ETRS89, European
Content-Crs
EPSG:28992
RD/Amersfoort, Dutch
The preferred CRS for the geometry in the response (response body) is specified using the header Accept-Crs.
HTTP header
Value
Explanation
Accept-Crs
EPSG:4326
WGS84, global
Accept-Crs
EPSG:3857
Web Mercator, global
Accept-Crs
EPSG:4258
ETRS89, European
Accept-Crs
EPSG:28992
RD/Amersfoort, Dutch
12.4 CRS transformation
Certified software is available to the national government to transform between coordinate reference systems.
API-41: Use content negotiation to serve different CRSs
The CRS for the geometry in the response body is defined using the Accept-Crs header. In case the API does not support the requested CRS, send the HTTP status code 406 Not Acceptable.
13. Hypermedia
Dit onderdeel is niet normatief.
Note
The working group has indicated this extension to be stable.
Hypermedia relates to the use of hyperlinks (from now on called links) as part of a document's payload, which are essentially URIs pointing to other resources. Typically, but not necessarily, these links are retrievable (also called dereferencable) from the web over the HTTP protocol. We intentionally make a clear separation between navigation controls and external links. Both kinds can easily be combined as part of a single API.
API-70: Provide absolute URIs for hyperlinks
Only absolute URIs may be provided since this enables simple traversal of links by following URIs. While relative links are more compact and may be practical when having multi-environment deployments, they introduce extra complexity for the client and may potentially result in erroneous behaviour (e.g. when dealing with trailing slashes or dot segments). For the same reasons, absolute URIs may not be templated.
Note
This design rule does explicitly NOT intend the use of hyperlinks as an implementation of the often debated HATEOAS constraint, as described in the well-known REST thesis (Roy Fielding) or the Richardson Maturity Model (Level 3). An API specification must offer a strict and stable contract between server and client, which should guarantee backwards compatiblity during the full lifetime of a given major version, whereas true HATEOAS advocates continually evolving interfaces requiring little to no prior knowledge about how to interact with the application.
13.1 Navigation controls
Navigation controls are references to URIs within the scope of the originating API, i.e. these paths are typically specified in the same OpenAPI specification and thus residing on the same domain within the same base path. The main (and only) purpose is to increase discoverability by providing navigation links, which can be leveraged by client applications or by developers while building applications or evaluating APIs. Since internal links only serve a navigational purpose, they can only be provided as part of response messages.
Note
The only exception when navigation controls are allowed to point to other APIs is when they share governance and security context. When doing so, the governing party must guarantee stability of links between the APIs, which means the target operation of navigational links may never change during the lifetime of (a major version of) the originating API. They must also share the same security context, otherwise clients have to exchange mixed credentials for different endpoints.
API-71: Support the HAL media type for every GET response
The [HAL] standard is a universal and widely adopted standard for serializing hyperlinks in JSON responses. As standardized by the HAL specification, navigation controls must be provided in a dedicated links-container, named _links. This introduces a clear separation between the data and the interface controls, preventing possible naming conflicts. Link objects can reside on any level in the JSON tree. HAL response messages must explictly specify the corresponding media type.
For example, a book resource may provide a self-referencing link.
Navigation controls should not be intermixed with functional identification. Information resources represent real-world entities, which are functionally identified outside the context of an individual API. The same entities may be exchanged via other channels or other (versions of) APIs, providing the same functional identifiers.
API-72: Provide at least an href attribute for every link object
A link object must at least contain an href attribute with an absolute URI as value. Additionally, a title attribute may be provided for providing a human-readable description of the link. Other attributes should not be used.
API-73: Provide self-referencing links for all resources
In case a JSON object represents an entity which is exposed as an individual resource within the API, a self-referencing link with relation type self must be provided. This includes resources which are (partially) embedded in other resources. Self-referencing links typically do not contain a title attribute.
For example, a book resource may provide a self-reference for itself and for its author (which resides in a nested object).
API-74: Provide navigational links pointing to GET operations only
Navigation controls may be provided, only when pointing to read (GET) operations. Other operations require more prior knowledge for client applications to be able to use them in a meaningful manner.
API-75: Only provide navigational links when there is a clear functional goal
While it might be tempting to provide navigation controls for every possible client interaction, navigation links must be added sparingly. Only when there is a clear functional goal / added value, additional navigation controls should be provided.
13.2 External links
External links are references to URIs outside of the scope of the originating API. These links can point to literally any location on the web; they may even point to URIs which are not dereferencable at all (e.g. in case they are used as a universal identifier only). A few examples:
Links to related documents, such as images, PDF documents etc.
Links to HTML web pages, providing human-friendly content
Links to universal standards, such as RDF vocabularies
API-76: Treat external links as regular resource attributes
External links must be considered in the same way as regular resource attributes.
For example, a book resource may provide a link to the cover image:
API-42: Provide standard navigation controls for pagination
For collection resources, navigation controls must be provided to simplify pagination for client applications. The standard link relation types next and prev (see [IANA-RELATIONS]) must be used if relevant. When no next or previous page exists, the link must be fully omitted. By providing standard links, clients can build and re-use generic pagination components, regardless of the pagination strategy (e.g. offset or cursor-based).
For example, a collection resource for books provides a self and next link. Since this is the first page, no prev link is provided.
Providing the total count and/or last page of a collection should be considered carefully, since this may have a considerable impact on performance when dealing with larger collections. Therefore, providing such information or links is generally discouraged. Most often, this is not a problem since this does not add significant value for end users. Most modern user interfaces provide next/prev links only (e.g. a load more control).
15. Caching
Dit onderdeel is niet normatief.
Warning
This extension is in development and may be modified at any time.
For some resources, caching is required. HTTP provides default mechanisms for caching. Furthermore, both clients and infrastructure already handle these mechanisms by default.
The requirements to leverage these default caching mechanisms:
Add a few HTTP response headers;
Handle a few HTTP request headers.
There are 2 ways to implement caching: ETag and Last-Modified.
15.1 ETag
An ETag (Entity Tag) is a hash code or checksum of a resource. A modification of a resource results in another ETag. Hence, an ETag is unique to a particular version of a resource. Returning a resource, the ETag is added as the HTTP header ETag. The client caches both the resource and the ETag. Requesting the same resource, this ETag is supplied in the HTTP request header If-None-Match. The server matches the ETag in the HTTP request header If-None-Match to the ETag for the resource available to the server. In case these match, the server returns a HTTP response status code 304 Not Modified terug. The client retrieves the resource from its own cache. This only applies to client-side caching, in case the client sends the request headers along, otherewise it receives an HTTP status code 200 OK.
15.2 Last-Modified
It works just like ETag, but uses timestamps instead. The response HTTP header Last-Modified contains a timestamp that corresponds to the RFC 1123 notation and is valided against the request HTTP header If-Modified-Since. The server checks whether the resource has been modified since the timestamp provided. If not, the server returns an HTTP status code 304 Not Modified. The client retrieves the resource from its own cache. This only applies to client-side caching, in case the client sends the request headers along, otherewise it receives an HTTP status code 200 OK.
API-43: Apply caching to improve performance
For caching apply the default HTTP caching mechanisms using a few additional HTTP headers (ETag or Last-Modified) and functionality to determine wether a few specific HTTP headers are supplied (If-None-Match or If-Modified-Since).
16. Rate limiting
Dit onderdeel is niet normatief.
Warning
This extension is in development and may be modified at any time.
APIs limit the amount of requests that can be sent within a particular time frame to prevent server overload and to guarantee a high service level. APIs may track a rate limit (quota) per month that is enforced per 60 second time interval.
HTTP headers communicate the rate limit to the users.
HTTP header
Explanation
X-Rate-Limit-Limit
Amount of client requests per time frame
X-Rate-Limit-Remaining
Amount of remaining client request in the current time frame
X-Rate-Limit-Reset
Amount of remaing seconds in the current time frame
API-44: Apply rate limiting
To prevent server overload and to guarantee a high service level, apply rate limiting to API requests.
[rfc6585] introduces an HTTP status code 429 Too Many Requests to inform users the rate limit has been reached.
API-45: Provide rate limiting information
Use the HTTP header X-Rate-Limit to inform users of rate limits. In case the rate limits are exceeded, send the HTTP status code 429 Too Many Requests.
16.1 Expose API-key
API keys are "unrestricted" by default. There are no usage restrictions and these API keys should therefore not be exposed in a web application. Using API keys without usage restrictions in JavaScript creates a real change for abuse and quota theft. To prevent this, restricted API keys should be issued and used.
API-49: Use *public* API-keys
In JavaScript, only use *restricted* API-keys, linked to specific characteristics of the client-application (web application or mobile
application), e.g. a clientId and/or referring URL.
17. Error handling
Dit onderdeel is niet normatief.
Warning
This extension is in development and may be modified at any time.
Like a Web page displays useful error messages to visitors in case of an error, an API should return useful error message in a known and manageable format. The representation of an error is no different from the representation of a random resource, but with a particular set of fields.
APIs should always return useful HTTP status codes. HTTP status codes are divided in two categories:
400 range: content errors
500 range: internal server errors
A JSON representation of an error should contain a few details to assist developers, operators, and users:
A unique error type formulated as a URI pointing to further informtion in external (HTML) documentation;
A short, but useful error message;
A detailed description of the error (that assists in solving the issue);
A unique identifier formulated as a URI point to the specific occurence of the error (the error instance). Preferably, the URN should only allow authorized users to search the error logs.
The base for these default formats is [rfc7807]. A JSON-representation of an error is formulated like the following object:
{
"type": "URI: https://content.omgevingswet.overheid.nl/id/[/{categorie}]/{fout}",
"code": "Systeemcode die het type fout aangeeft",
"title": "Hier staat wat er is misgegaan",
"status": 401,
"detail": "Meer details over de fout staan hier",
"instance": "urn:uuid:ebd2e7f0-1b27-11e8-accf-0ed5f89f718b"// The error instance
}
Validation errors for POST, PUT, and PATCH requests are specified per field. The full list of errors is returned concurrently. The response consists of a fixed top level and error code for validation error and additional error fields with detailed errors per field:
{
"type": "https://content.omgevingswet.overheid.nl/id//ValidatieFout",
"title": "Hier staat wat er is misgegaan…",
"status": 400,
"invalidParams": [{
"name": "voornaam",
"code": "Systeemcode die het type fout aangeeft",
"reason": "De voornaam mag geen speciale karakters bevatten."
}, {
"type": " https://content...//fouten/validatie/Wachtwoord",
"name": "wachtwoord",
"reason": "Het wachtwoord is verplicht."
}],
"instance": "urn:uuid:4017fabc-1b28-11e8-accf-0ed5f89f718b"// De fout-instantie
}
API-46: Use default error handling
API support the default error messages of the HTTP 400 and 500 status code ranges, including the parsable JSON representation
[rfc7807].
17.1 HTTP status codes
HTTP defines a range of default status codes for APIs. These assist users to of the APIs to handle errors.
API-47: Use the required HTTP status codes
APIs should at least support the following HTTP status codes: 200, 201, 204, 304, 400, 401, 403, 404, 405, 406, 409, 410, 415, 422, 429, 500, and 503.
Summary of HTTP operations and the primary HTTP status codes:
Operation
CRUD
Full collection (e.g. /resource) specific item (e.g. /resource/\<id>)
POST
Create
201 (Created), HTTP header Location with the URI to the new resource (/resource/\<id>) 405 (Method Not Allowed), 409 (Conflict) in case the resource already exists
GET
Read
200 (OK), list of resources. Use paging, filtering and sorting to ease the handling of large collections 200 (OK) single resource, 404 (Not Found) if the ID does not exist or is invalid
PUT
Update
405 (Method Not Allowed), except for the purpose to modify or replace every resource in a collection 409 in case a modification is not possible due to the current state of an instance 200 (OK) or 204 (No Content), 404 (Not Found) if the ID does not exist or is invalid
PATCH
Update
405 (Method Not Allowed), except for the purpose to replace the full collection. 409 if a modification is not possible due to the current state of an instance. 200 (OK) or 204 (No Content), 404 (Not Found) if the ID does not exist or is invalid
DELETE
Delete
405 (Method Not Allowed), except for the purpose to remove the full collection. 200 (OK) or 404 (Not Found) if the ID does not exist or is invalid
A short list and description of HTTP status codes:
HTTP status code
Description
200 OK
Response to a successful GET, PUT, patch or DELETE. Also suitable for POST that does not result in a creation
201 Created
Response to a POST that results in a creation. Should be combined with a location header that points to the location of the newly created resource
204 No Content
Response to a successful request that does not return content (e.g. a DELETE)
304 Not Modified
If HTTP caching headers are applied
400 Bad Request
The request is invalid, e.g. in case the request (body) cannot be interpreted
401 Unauthorized
If no or invalid authentication credentials are supplied. Also useful to display an authentication window if the API is used in a Web browser
403 Forbidden
Response to a successful authentication, but the verified users is not authorised to access the resource
404 Not Found
Response to a request for a non-existing resource
405 Method Not Allowed
Response to an HTTP method that is not allowed for the authenticated user
406 Not Acceptable
Reponse to an unsupported format request (part of content negotiation)
409 Conflict
The request cannot be handled due to a conflict with the current state of the resource
410 Gone
Indicates the resource is no longer available at the requested endpoint. Useful top level response to requests for previous API versions
412 Precondition Failed
The preconditions supplied in one or more fields in the request header have been omitted or failed upon validation by the server
415 Unsupported Media Type
If the wrong content type is supplied as part of the request
422 Unprocessable Entity
Response to a request (body) that is correct but that cannot be handled by the server
429 Too Many Requests
Response if the rate limit has been exceeded.
500 Internal Server Error
If an unexpected error occured and server cannot respond.
503 Service Unavailable
If an API is not available (e.g. due to planned maintenance)
18. Signing and Encryption
Dit onderdeel is niet normatief.
Warning
This extension is in development and may be modified at any time.
Signing and encryption are mechanisms that can provide additional security on top of the transport layer security that is provided by HTTP TLS in combination with some form of authentication and authorization.
In this API strategy we concern ourselves with RESTful APIs. In RESTful APIs you request the current value of a resource. This is different from SOAP based protocols where content is transported using messages. Using SOAP part of or all of the content is signed and/or encrypted by the sender of the message. This has utitlity as there are no pre conceptions about resources and their behaviour. When using REST you have to ask yourself what is being signed or encrypted. The value of a resource at a certain date and time. Does this have utility above and beyond the transport layer security thats already there?
[Opmerking: Je voert via een RESTful API een operatie uit op een resource, Het kan bv ook gaan om een update/delete/insert op een resource waarbij controle op integriteit van zowel operatie als resource URL wenselijk/zinvol is vanuit security perspectief]
Because in RESTful API's you operate on a resource with read, insert, update, delete commands it can be necessary to especially protect against manipulation by signing the http header containing the operation (eg. command GET/POST/PATCH/DELETE) and the resource-URI along with additional header and payload data.
Be aware that signing and encryption are "expensive". There is a performance hit (especially for encryption), but most of all in the real world implementation of an API using these security methods will be more expensive. Knowledge among programmers is usually not complete, leading to extra time learning new skills. The added complexity leads to all manner of extra possibilities to create incorrect code, meaning testing will take longer.
Have a long hard look at alternatives to the technical solution of signing and encryption before commiting to using them.
can the same goals be achieved using different (better) software architecture?
can the goals be achieved using (business) contracts, audits etc... ?
The alternatives above may seem expensive as well but in practice could be cheaper.
18.1 Signing
Signing can be used to achieve:
authentication: Establishes the identity of the original sender of a request/response even when send through intermediaries.
integrity: allows the receiver of a request/response to establish that the request/response (or parts there of) have not been tampered with
non-repudiation: ensures that the sender of a request/respons cannot plausibly deny that a request/reponse (or parts thereof) was sent by him.
18.1.1 Detached, Enveloping and Enveloped signatures
Generally speaking there are three distinct types of signature: Detached, Enveloping and Enveloped.
A signature can be detached, that is the signature is separate from the content it is signing.
Signatures can be enveloping, that is the content being signed is contained within the signature itself. The last option is an enveloped signature, that is the signature structure/element is contained wihin the content that is signed.
18.1.2 Canonicalization
Canonicalization(C14n) ensures that syntactically irrelavant information such as trailing whitespaces, different line terminators or tabs do not invalidate a signature. This is especially important with detached signatures where a different rendering of (semantically) the same content can invalidate a signature. A C14n algorithm ensures semantically identical content receives the same signature.
18.1.3 Signing within encoding formats
When signing takes place within an encoding format the way information is exchanged(e.g. through APIs) is not directly relevant to the way signatures are applied. The API design rules do not currently express any normative preference for encoding formats. We do have the JSON extension that expresses a non normative preference for JSON. Therefor we do include information on signing within the two most common encoding formats (XML & JSON) themselves even if it is not directly related to APIs.
18.1.3.1 Signing XML
The standard for XML digital signatures allows for Detached, enveloping and enveloped signatures of any XML format. https://www.w3.org/TR/xmldsig-core1/
When using a specific XML encoding format (or instance GML for geograpic information) one should be aware that when this specific XML format was not made with digital signatures in mind it may be very difficult to implement digital signatures.
For instance for enveloped XML digital signatures most implementations expect the signature element as either the first or last element of the XML root element. An encoding standard such as GML currently does not allow users to add a signature element to the root of an xml document. Making XML signatures practically unimplementable using standard software.
18.1.3.2 Signing JSON
18.1.4 Signing requests/response
18.1.4.1 Signing requests/respone with knowledge of encoding format